Everyone Survives the Correction, Except the People Who Built It
The labs spending $725 billion to defend the frontier are the least safe seat in the AI economy. Here's why.


Michael Mauboussin has been teaching the same trick for thirty years: When you face an outcome that depends on a long causal chain, do not try to predict the chain. Look at what happened to everyone else who stood at the same starting point. He calls this the base rate.
The base rate question for AI investment in 2026 is not anymore whether the technology works. I tried in the first four posts in this series to establish that it works in some places, fails quietly in others, and operates on at least three independent clocks. The question is which of the companies currently inside the AI economy will still be inside it after the correction the markets are slowly pricing.
I want to give that question a structure, because answering it well requires resisting two temptations.
The first is talking about AI as a single category.
The second is using words like winner and loser, which obscure what actually happens when a sector recapitalizes.
Many so-called losers in the dot com correction survived. Most just lost ninety percent of their market value and traded sideways for a decade.
Five archetypes are worth distinguishing, because each has a different profile under the three pressures that decide who makes it out: moat strength, revenue quality, capex dependency.
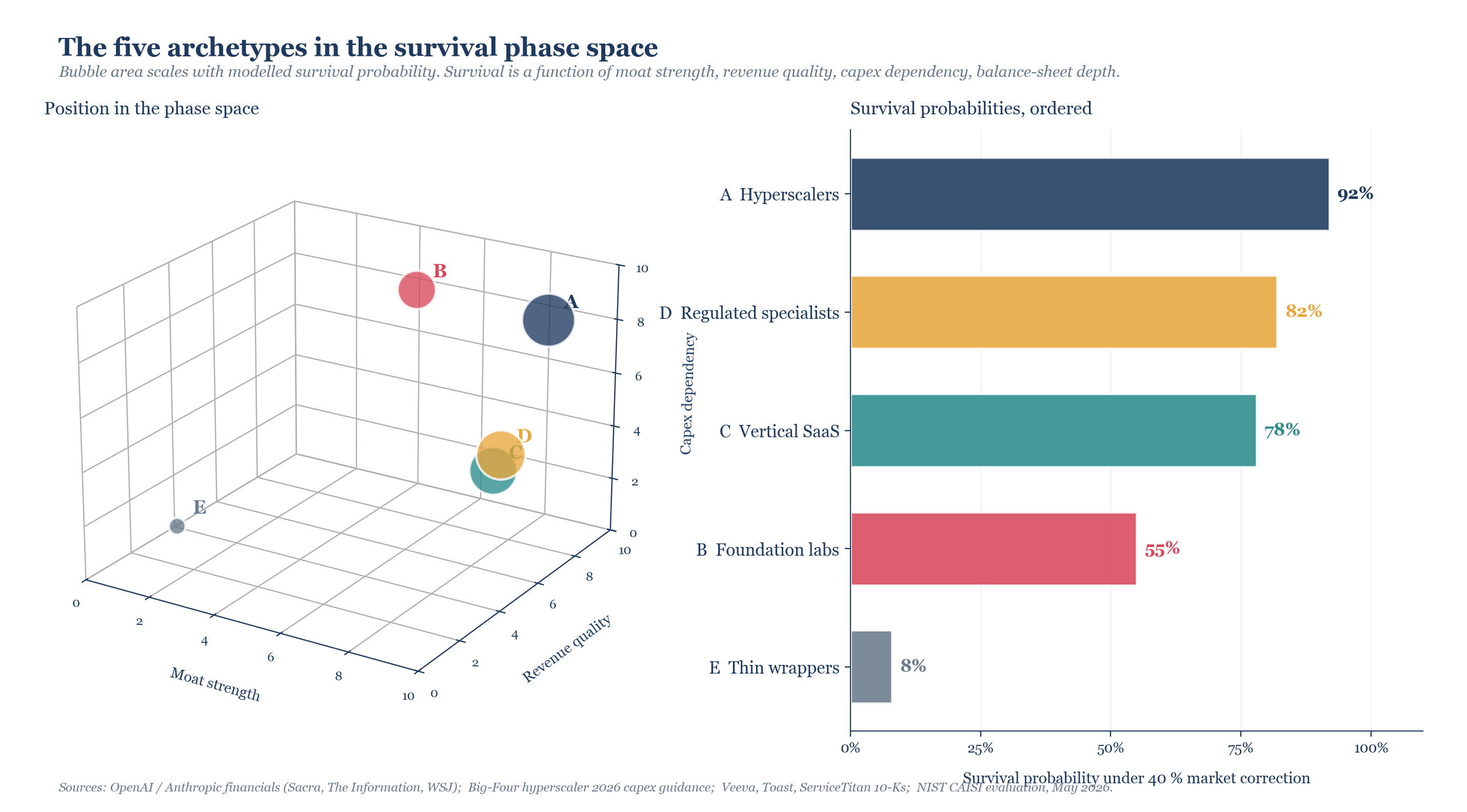
Hyperscalers are cloud platforms whose AI is one segment of a larger profitable machine. Foundation labs build frontier models and sell tokens. Vertical SaaS companies own a specific industry workflow and added AI on top. Regulated specialists do something AI-shaped inside a regulatory moat. Thin wrappers are a UI on someone else’s API.
The survival bars are conditional probabilities under a forty percent correction concentrated on the AI complex, lasting twelve to eighteen months. A sixth category exists, but it does not belong in this phase space. I will come to it after the five.
The five, briefly
Hyperscalers (92% survival) are the easiest case. Microsoft, Google, Amazon are profitable multi-decade businesses whose AI investments sit on top of a base that already works. They are betting the marginal capex line, not the company. That line is, however, enormous: Big Four 2026 capex guidance reached roughly seven hundred and twenty five billion dollars. The question that should make a hyperscaler CFO uneasy is what happens to depreciation schedules if inference costs keep falling as fast as they have been. Microsoft fell twelve percent in a single day in January 2026 when it disclosed that forty five percent of its six hundred and twenty five billion dollar cloud backlog was tied to OpenAI. They survive corrections because they are diversified. The corrections still cost them money.
Foundation labs (55%, with very wide internal spread) are not one archetype but at least two. OpenAI’s annualized revenue ran at twenty five billion dollars in early 2026 against fourteen billion in cash burn, with revenue partly made of Microsoft Azure compute credits that never leave the ecosystem. Anthropic ran thirty billion in annualized revenue, ninety percent enterprise, with burn projected at three billion against five and six tenths in 2025, and management guidance pointing to cash breakeven in 2027. These are not the same company. xAI is structurally weaker than either. The spread inside the archetype is at least as wide as the spread between archetypes.
Vertical SaaS (78%) is the interesting case. Ben Thompson’s Aggregation Theory says the most valuable position is the one that owns the user relationship, not the one that owns the underlying technology. Veeva in life sciences, ServiceTitan in field services, Toast in restaurants own workflows that took fifteen years to build. The AI feature is a layer on top of a workflow they already owned. Their value proposition was never their model. It was their workflow and their data. If the underlying intelligence becomes a commodity, vertical SaaS buys it cheaper from whoever is selling it and continues to capture the customer relationship that was always the actual asset.
Regulated specialists (82%) sit awkwardly between vertical SaaS and foundation labs. Palantir, Tempus AI. They have proprietary data flows, customer relationships that took years to build, regulatory moats that compound. The stickiness that comes from regulation is not flashy, but it survives sentiment shocks better than almost anything else. The same regulation that protects them confines them, which is fine for survival-focused investors and less fine for anyone who priced these companies for hypergrowth.
Thin wrappers (8%) barely require analysis. Median GPT wrapper has a ninety day churn rate of roughly sixty five percent. The moat is whatever weekend’s worth of code differentiates one prompt-template-plus-Stripe-integration from the next. By March 2026 venture capital had essentially stopped funding them. The correction does not kill them. It removes the venture capital that was keeping them on life support. The interesting question is what happens to the ones that pivot. Cursor became a coding assistant by going deep into developer environments. Harvey became a legal product by ingesting client case histories. The pattern is the same: the wrapper became a product when it stopped being about the model and started being about everything around the model.
Open source moved faster than anyone budgeted for
The survival analysis above assumes foundation labs have meaningful pricing power on their models. That assumption is decaying fast. In April 2026 DeepSeek released V4. In May Alibaba released Qwen 3.5. Both match GPT-5.5 on most benchmarks. The NIST CAISI evaluation pegs DeepSeek V4 Pro at roughly eight months behind closed frontier on aggregate capability, smaller than the spread inside the open-weight tier itself eighteen months ago.
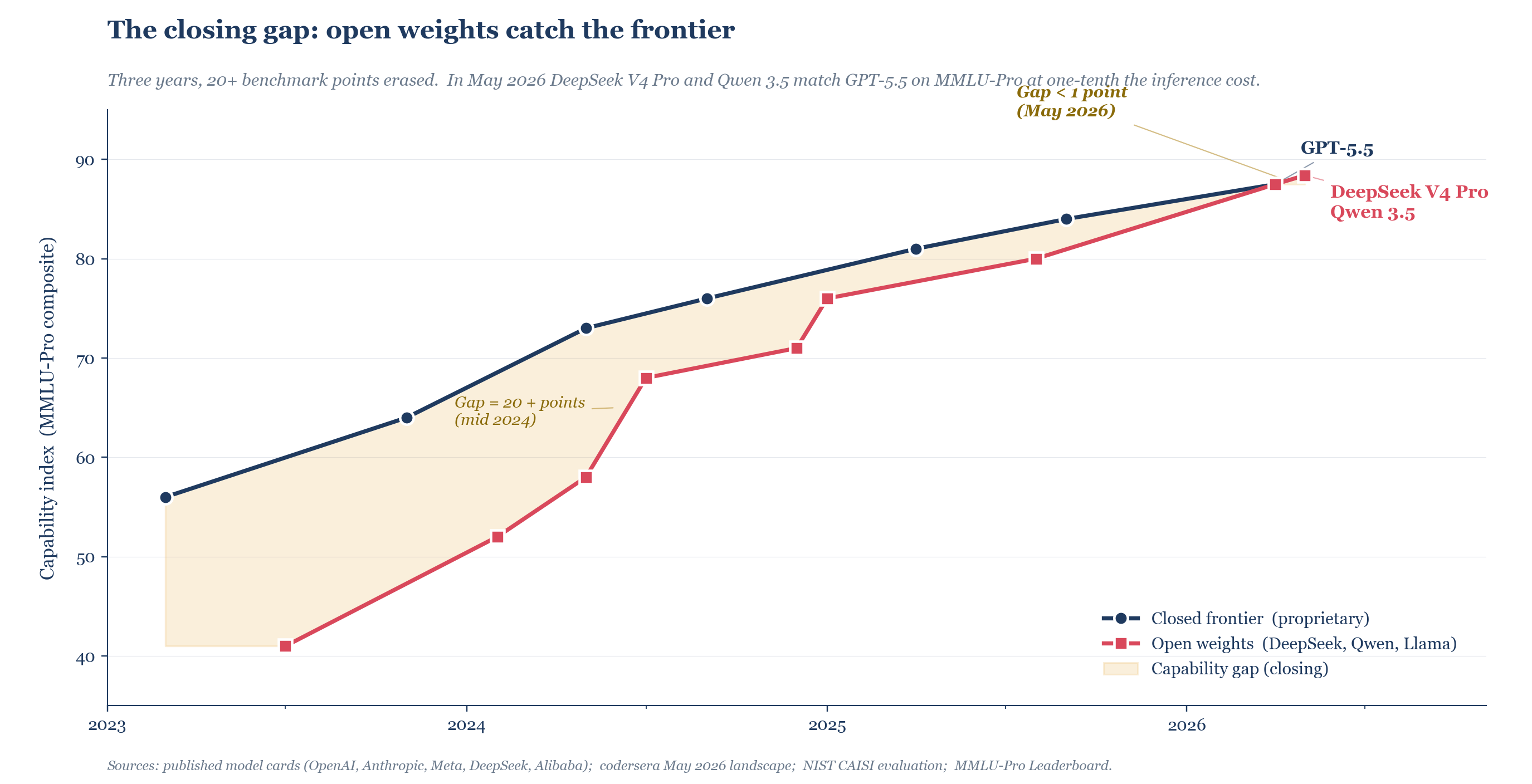
In mid 2024 the gap between closed frontier and best open-weight was more than twenty points on MMLU-Pro. By May 2026 it was under one point.
Emad Mostaque, who founded Stability AI and left it to work specifically on AI concentration, has been making this argument since 2023. The cost of intelligence is approaching the cost of electricity. Closed models are valuable to the extent they remain meaningfully better than open models, and only to that extent. His sharper structural claim, repeated through 2025 and into 2026, is that the training capacity major labs have committed for 2026 to 2028 exceeds plausible commercial demand by something on the order of forty percent. The compute foundation labs are using to defend the frontier is the compute that will eventually have to be written down when the frontier itself stops being defensible.
Kai-Fu Lee has been arguing a different, complementary point. The durable structure of AI is a US-China duopoly, but not the duopoly the conventional narrative describes. The conventional narrative places OpenAI and Anthropic in one seat and a Chinese closed lab in the other. Lee’s claim is that the Chinese seat is being filled by open-weight providers, not by closed labs. DeepSeek V4 Pro and Qwen 3.5 are not lagging Chinese answers to GPT-5.5. They are the structural alternative. The corollary is uncomfortable for American foundation labs: if the durable equilibrium has open weights on one side and closed labs on the other, the closed labs are competing against a price structure they cannot match, on the side of the market that historically loses when the input commodity collapses.
If open-weight models are within a percentage point of frontier capability and cost ten times less to serve, foundation lab revenue from API access has a ceiling determined not by what the market will pay for intelligence, but by what enterprises will pay for the differentiated last mile of intelligence. That last mile is real. It is also not where the current valuations come from. The framework I just described has five positions competing for the same surplus. What the framework does not see is who sells them the map of the field.
The sixth archetype that nobody is pricing
There is a category in the AI economy of 2026 that the framework above does not contain because it operates on the framework rather than inside it.
Call it the governance supplier. The job is not to build AI, deploy AI, wrap AI, or own a workflow around AI. The job is to measure AI in production, continuously, with the kind of formal mathematical discipline that the systems being measured do not themselves possess. The job is to do for non-deterministic systems what statistical process control did for manufacturing in the 1950s. Without that layer, none of the other five archetypes can demonstrate to a regulator, an auditor, or a board that the system they deployed last quarter is still the system they deployed last quarter.
This matters more in a correction than in a boom. During the boom, governance is a cost center everyone underfunds. During a correction, governance is the layer that decides which deployments stay in production and which get pulled. That is most of regulated industry. It is most of finance. It is all of pharma. It is increasingly defense, energy, and critical infrastructure. The category is not narrow. It is just underbuilt.
The reason it is underbuilt is that auditing a non-deterministic system requires mathematical tools the dominant auditing methodologies do not contain. ISA procedures, SOX controls, model risk management frameworks from the deterministic era: all assume that running the same input twice gives the same output twice. LLMs do not. The discipline required is not new. Fisher-Rao geometry has been available since 1945. Bayesian online changepoint detection since 2007. Shannon entropy as a drift signal since 1948. The work is assembling these into a deployable continuous monitoring stack and convincing enterprise buyers that the stack is load-bearing rather than discretionary.
The gap between what conventional monitoring sees and what information-theoretic monitoring sees is not theoretical. I ran a small replicable experiment on a synthetic financial-document classifier. The setup is simple. One thousand short documents are generated and labelled with credit-risk categories. A classifier is trained on the first one hundred days. Over the following six hundred days, the language describing credit risk drifts from the conservative-reserve register of IAS 39 to the expected-credit-loss register of IFRS 9. This is a real transition audited reporting went through between 2014 and 2020. The underlying labels remain valid. Only the linguistic surface moves.
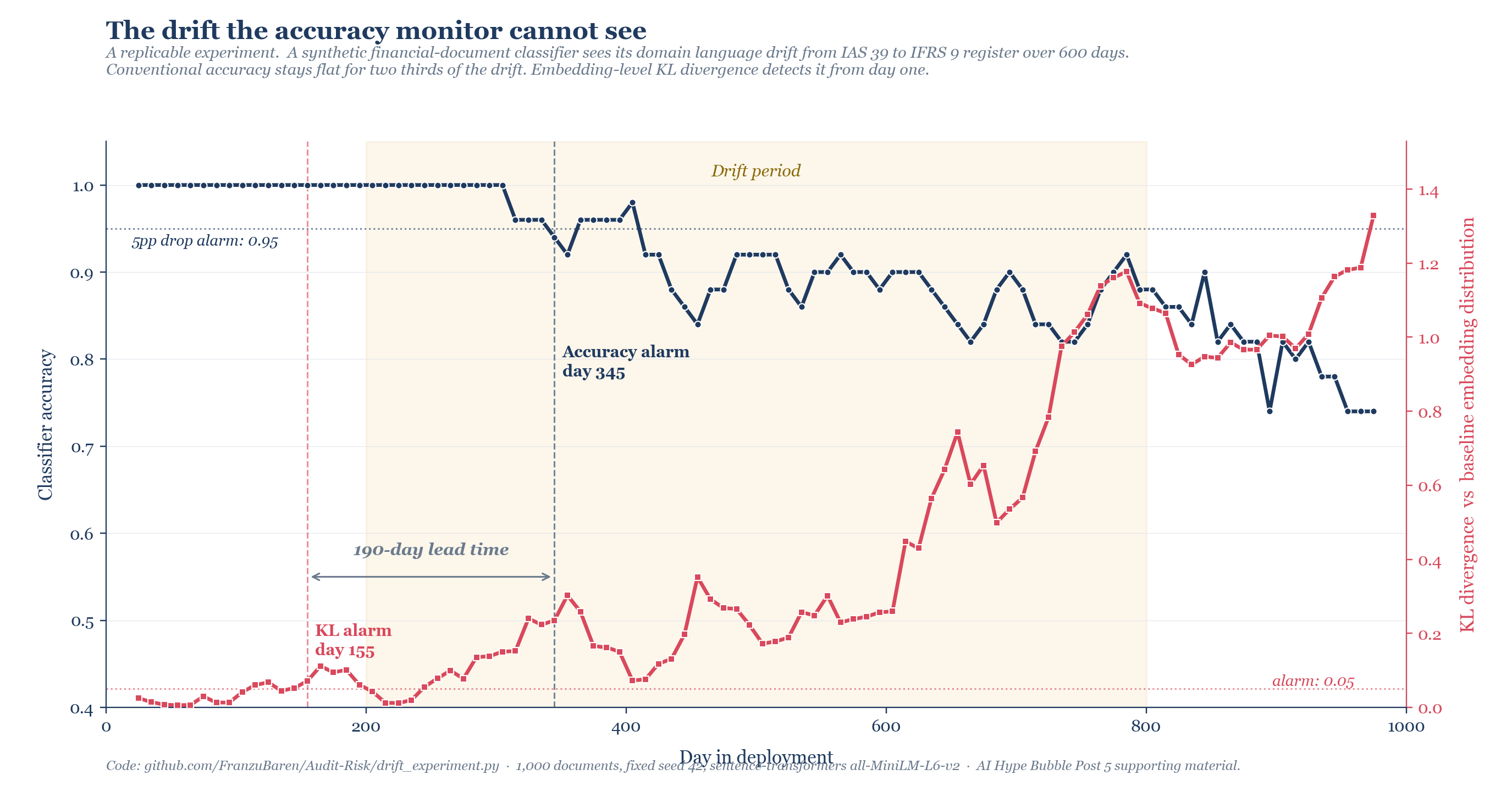
Conventional accuracy monitoring sees nothing for the first two hundred days of the drift period because the classifier continues to perform well on most of the corpus. Embedding-level KL divergence against baseline begins rising from day one and crosses an alarm threshold at day 155. Accuracy does not drop by five points until day 345. The KL monitor provides an early warning of 190 days, roughly six months of operational runway during which a responsible team would investigate, retrain, or recalibrate before any conventional metric tells them anything is wrong. The discipline that makes this lead time visible is one hundred lines of Python and a free sentence-transformer.
The market sizing falls out of the historical base rate. By 2006, four years after Sarbanes-Oxley, US compliance spending reached six tenths of one percent of revenue in regulated public companies, an increment of half a percentage point over the pre-SOX baseline. By 2024, model risk management was running at three to five tenths of one percent of banking revenue, tools alone at one and seven tenths of a billion dollars, AI-specific MRM already at five and nine tenths of a billion in 2025. Apply that same range, three to six tenths of one percent, to the roughly thirty trillion dollars of global revenue in regulated industries that will have deployed AI in production by 2030. Assume the AI-specific share of governance converges to thirty percent. The implied global AI governance market lands between twenty seven and fifty four billion dollars in annual revenue by 2030. Same order of magnitude as the entire global SaaS category was in 2018, built from a regulatory floor that already exists.
The geometry of standing still, in this category, is different from the geometry of standing still in the other five. The other five stand still by occupying a defensible position before the music stops. The governance suppliers stand still by occupying a position that did not exist before the music stopped, and that the music stopping creates.
The Mauboussin quadrant
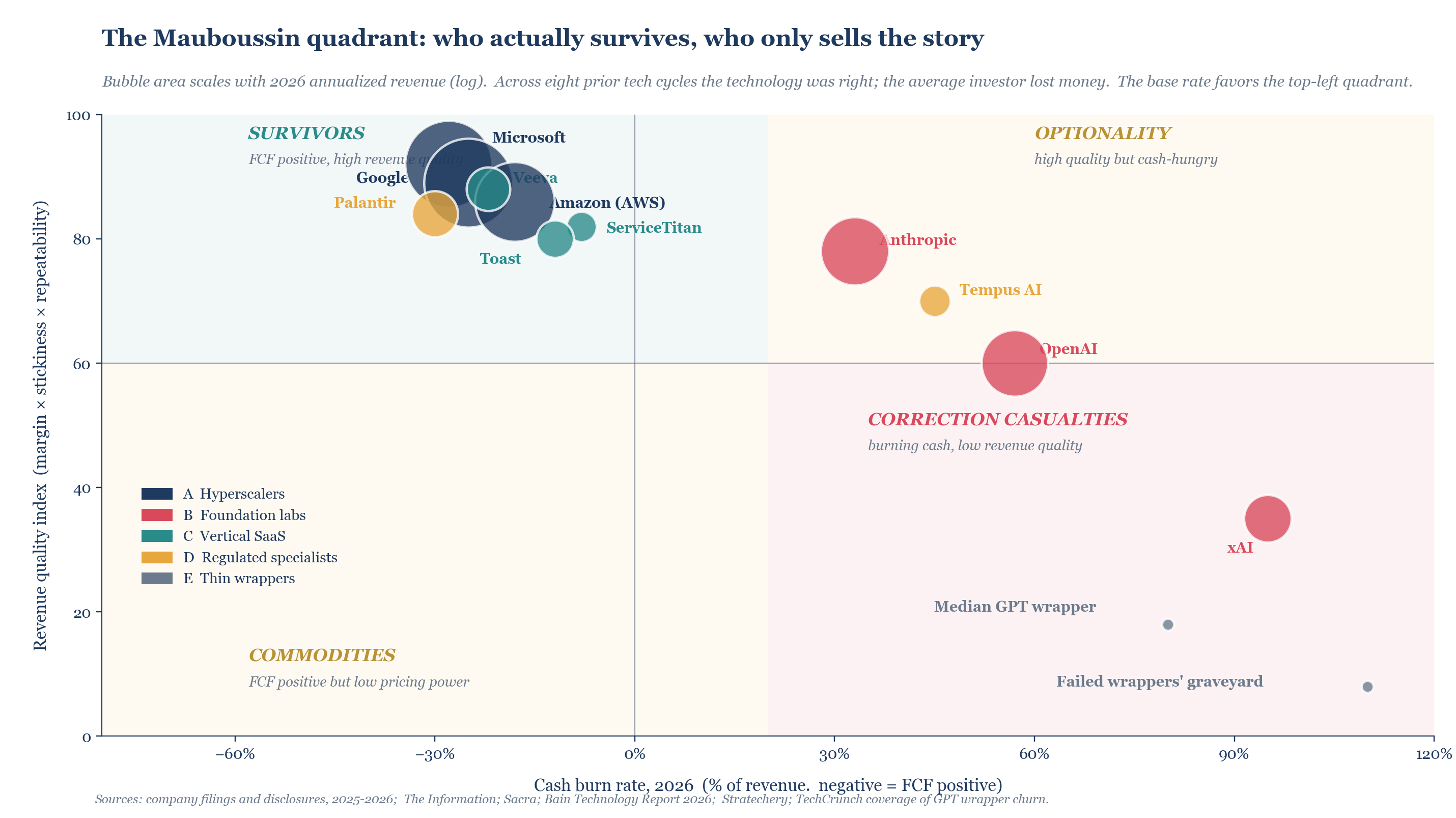
Think of placing companies in two dimensions: cash burn as a percentage of revenue, and a composite revenue quality index combining gross margin, customer stickiness, and pricing power. Across the eight major technology cycles of the last thirty years, the technology was almost always right and the average investor almost always lost money. The quadrant tells you why. The position that pays in a correction is the top left: high revenue quality, free cash flow positive. That position is occupied by hyperscalers and vertical SaaS, not by foundation labs.
Clayton Christensen used to say something that helps here. The companies that get disrupted are not the bad companies. They are the good companies that listen to their best customers and invest in what those customers want. The companies that disrupt them come in at the bottom of the market and move upmarket. In AI 2026, the foundation labs are disruptive to legal research firms, first-line customer support, document drafting. They are not disruptive to clinical trial management systems, point of sale software, or defense contractor analytics. The vertical SaaS moat holds where the underlying workflow is regulated, industry-specific, and dense with proprietary data the foundation labs do not have and will not get.
Next and Last Episode (for the AI Bubble Serie)
The framework here is structural. It describes the geometry of the surviving economy after a correction that has not yet happened. Standing still is not the end of the story. It is the precondition for what gets built next.
Last post for this serie is the rest of the story. It runs a different toolkit on a different question. Where this post used survival probabilities under a hypothetical correction, the next one uses persistent homology on the consolidation dynamics that follow it. The same mathematics that detects topological features in noisy point clouds also detects them in industry consolidation patterns, and the result, when applied to the eight prior tech cycles in the Mauboussin dataset, gives a recognizable signature for which of the four possible post-correction equilibria actually formed. By Q2 2028 we will know whether the surplus migrated upward to the hyperscalers, sideways into vertical SaaS, downward into open-weight infrastructure, or into the governance category that did not exist on the map two years earlier.
My working hypothesis, which next will defend, is that the surplus does not migrate in one direction. It splits, asymmetrically, between two of the four directions, and the split is recognizable about eighteen months before the consensus narrative catches up to it. The companies that get there first are not the ones with the loudest 2026 valuations. They are the ones whose business model already assumed the correction was coming.
The interesting question after a correction is not whether the bears were right about the bubble. It is whether the bears were right about what came after. The dot com bears were correct about valuations and almost entirely wrong about the durable form of the internet. The AI bears in 2026 will likely be correct about valuations and may be entirely wrong about the durable form of AI. What replaces the chatbot monoculture of 2024 will probably look closer to what Yann LeCun has been arguing for since 2023 than to what Sam Altman has been selling. Embedded, grounded, specialized, continuously measured. Far less spectacular than the demos that defined the hype cycle, and far more important to the economy that will absorb it.