Voting with GPUs
Four assumptions, four critics, one underlying object. Is the bubble is a bet on its size?

Sam Altman is not lying to you, and this is the problem.
If he were, if the AI bubble were a classic fraud of the Enron-Theranos-FTX family, we would know what to do. There is a playbook. You wait for the short-sellers, you read the indictment, you watch the Netflix miniseries, you move on. We are not in that scenario. We are in a much more uncomfortable one: the people spending fifteen trillion dollars of market value on this bet genuinely believe they are doing the right thing, their belief has serious intellectual foundations, and the fact that none of them is lying is precisely what makes the situation structurally harder to resolve with the epistemic tools we have.
A fraud deflates when someone tells the truth. What deflates a good-faith bet? That is a more interesting question, and it is the question this post is about.
In Post 1 I argued that the bubble is not one bubble but three (infrastructure, application, narrative) running on three different clocks. That decomposition still stands. But it raises a question the post deferred: what is the market actually betting on when it marks these assets up? Not “AI will work,” full stop. Something narrower. Something specific enough to be wrong in specific ways.
The answer, as far as I can reconstruct it, is a set of four propositions, each of which has to hold for the capital allocation to make sense. Each of them has serious adherents and specific, empirical arguments in its favour. Each of them has serious critics and specific, empirical arguments against. On the surface they look like four different claims about four different things. I am going to argue, by the end of this post, that they are not four things. They are four projections of one thing. And that one thing is a quantity we can write down, measure, and watch move.
But first, the four. Here is the map of the territory. Each of the four assumptions has named defenders who have made its case in print, and named critics who have attacked it in print. I want you to see the debate on one page before we walk through it, because each section below develops one row of this table in narrative form. When we reach Section V, the unification will look different if you have this map in your head.
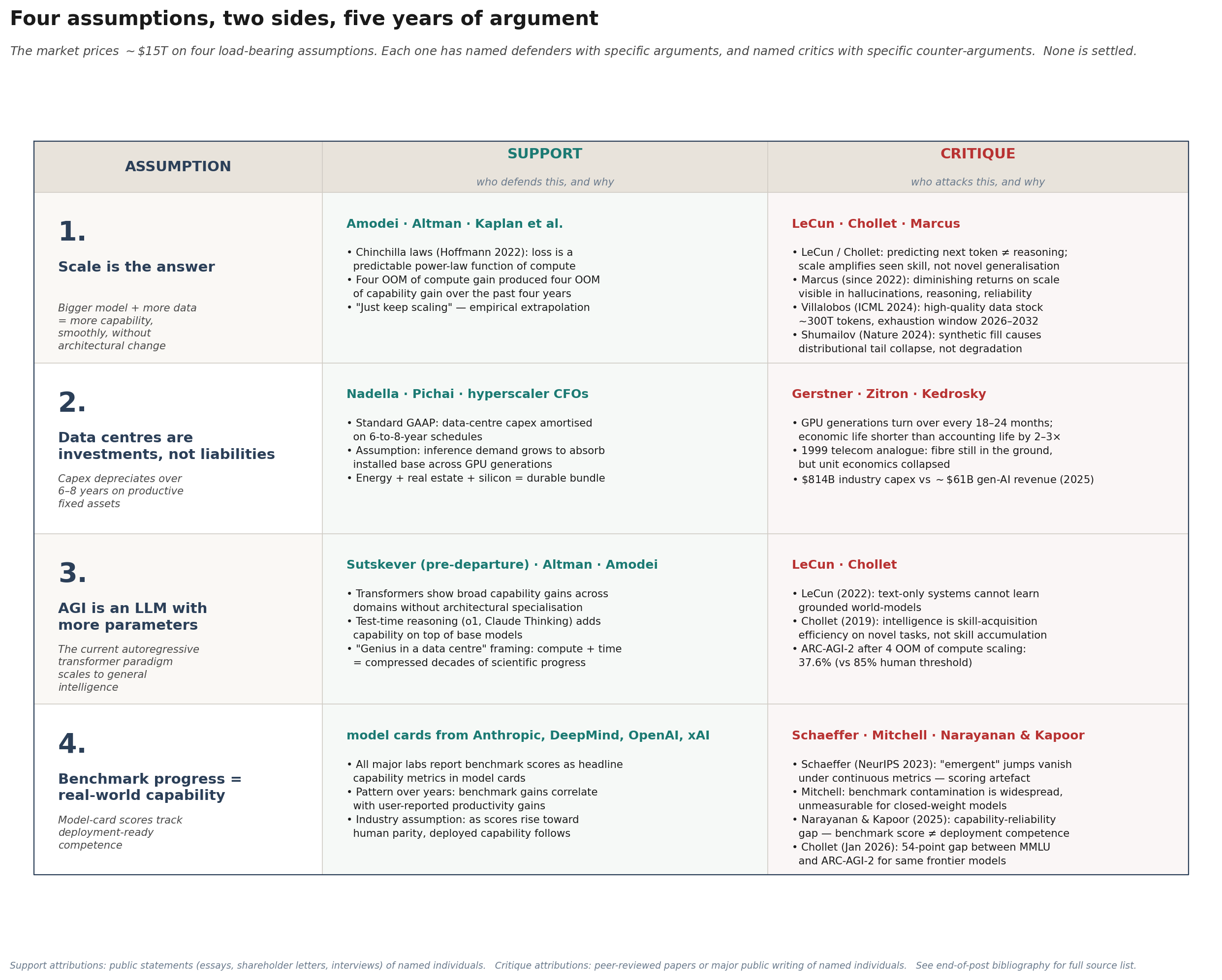
Scaling is the answer
This is the oldest and most institutionally embedded of the four. It holds that capability is a smooth function of compute: more parameters trained on more tokens produces more intelligence, without architectural reset, without qualitative change, without ceiling.
The empirical foundation is Hoffmann et al. (2022), the Chinchilla paper, which gave us a closed-form law for transformer loss as a function of parameters N and training tokens D:
The fit from DeepMind’s original experiments: A = 406.4, α = 0.34, B = 410.7, β = 0.28, E = 1.69. That E is the irreducible floor, the entropy of language itself. The other terms decay with scale.
Dario Amodei, in a widely-read 2024 essay and subsequent interviews, described this as “a new square in the periodic table.” Sam Altman has called scaling laws “physical laws.” Jared Kaplan co-authored the original 2020 paper that first showed the relationship empirically. The position of this camp is straightforward: the pattern has held for five years and four orders of magnitude of compute, and the reasonable extrapolation is that it continues.
The other camp objects on both philosophical and physical grounds.
Yann LeCun’s position, developed across the JEPA line of work, is that predicting the next token is not reasoning and never will be. You can make the prediction better. You cannot, through that act alone, make it reason. François Chollet makes a sharper version of the same argument: intelligence is skill-acquisition efficiency on genuinely novel problems, not skill accumulation on problems the model has seen. His benchmark, ARC-AGI, is the instantiation of that definition.
But the strongest objection is not philosophical. It is physical. The Chinchilla law has two decaying terms: one in N, one in D. You cannot just buy more compute; you have to buy it in the correct ratio with data. And data, unlike compute, does not scale on demand.
Villalobos and colleagues at Epoch AI (ICML 2024) estimated the effective stock of high-quality human-generated public text at around 300 trillion tokens, with an exhaustion window of 2026 to 2032 depending on how aggressively models are overtrained. Three hundred trillion is a large number until you notice that Chinchilla-optimal scaling at hyperscaler 2027 compute levels, on the order of 10²⁸ FLOPs, requires approximately that much data. The ceiling is not decades away. It is this decade.
Synthetic data does not rescue the math. Shumailov et al. (Nature, 2024) demonstrated that recursive training on synthetic data causes the tails of the original distribution to disappear, not degrade, disappear. The rare cases are the first casualties.
This is the simulation that earns its place in the post.
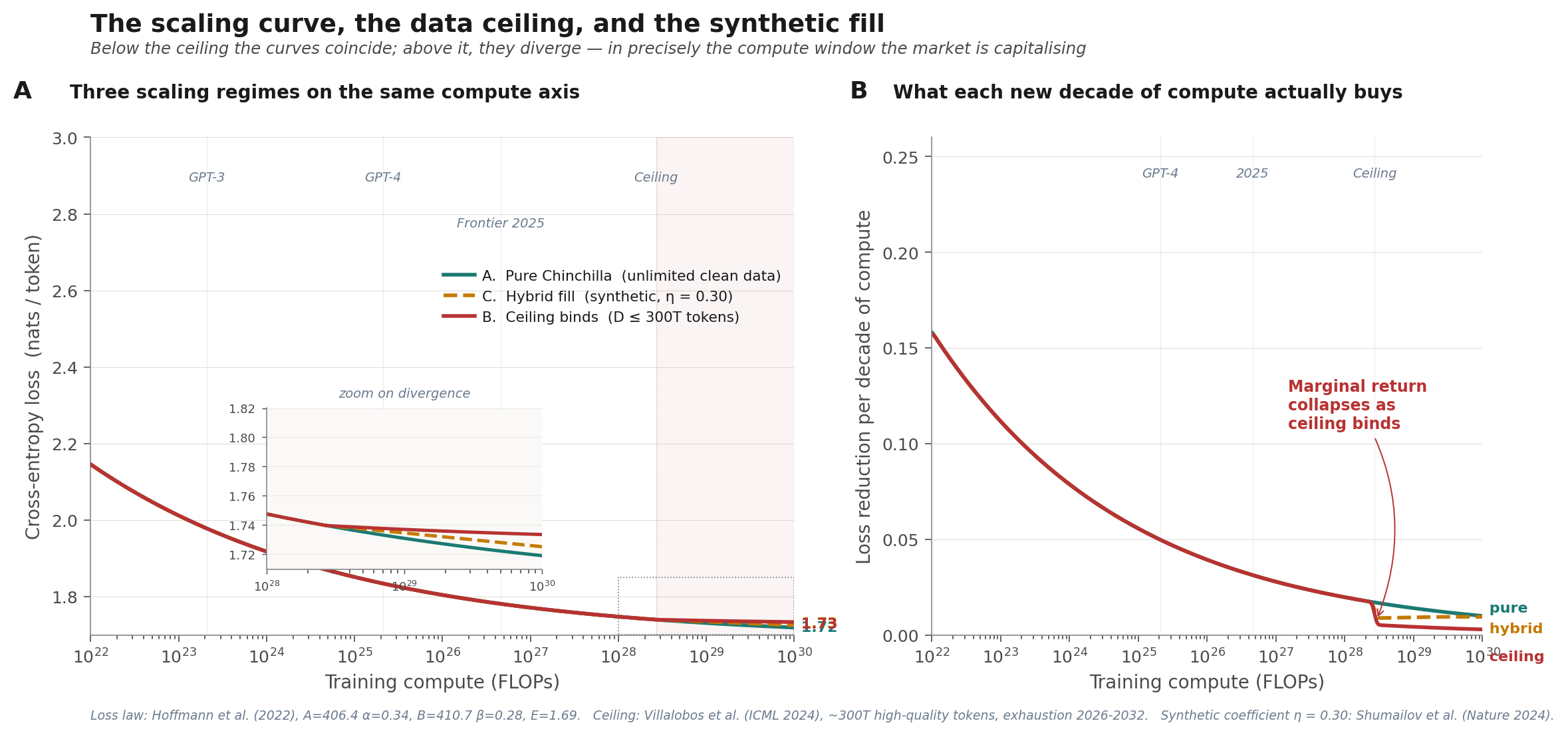
Three regimes of the same Chinchilla loss law on the same compute axis. Panel A: pure scaling with unlimited clean data; ceiling capped at 300T tokens; hybrid with synthetic fill at coefficient η = 0.30 (a lower bound from Shumailov’s experiments). Below the ceiling the curves coincide, which is an internal consistency check. Above the ceiling they diverge. The inset zoom shows the split happening between 10²⁸ and 10²⁹ FLOPs.
Panel B is the bubble-relevant view. The y-axis is marginal loss reduction per decade of compute: what you actually get for the next tenfold spending increase. Under pure scaling, that number declines smoothly. Under the ceiling regime, it collapses. Marginal return on compute drops from around 0.02 nats per decade to below 0.005 nats per decade, across the compute window the hyperscalers are pre-committing their capital.
This is the pillar under stress. Not broken, stressed.
Data centres are investments, not liabilities
The second proposition is narrower and carries more of the near-term dollar weight. Microsoft, Alphabet, Amazon, and Meta have collectively pledged capital expenditure of approximately one trillion dollars on AI infrastructure through 2027. Oracle has added hundreds of billions more. The accounting assumption embedded in this spend is that data centres are productive fixed assets. GPU capex depreciates over six years on buildings, power, and silicon, generating a return stream across that horizon.
In February 2025, Amazon announced (in its Q4 2024 earnings call, effective January 1, 2025) that it was shortening the useful life of a subset of servers and networking equipment from six years back to five. The stated reason, verbatim from the filing: “the increased pace of technology development, particularly in the area of artificial intelligence and machine learning.” The accounting change produced a $700 million hit to operating income in the first quarter alone. Amazon additionally recognised a $920 million accelerated depreciation charge in Q4 2024 for early-retired equipment.
Michael Burry’s Scion Asset Management, disclosed in November 2025, took $1.1 billion in put options against Nvidia and Palantir with an explicit thesis: hyperscalers are understating depreciation by an estimated $176 billion over 2026-2028 by extending useful lives beyond what the hardware actually supports. Burry’s framing: “Massively ramping capex through purchase of Nvidia chips on a 2-to-3-year product cycle should not result in the extension of useful lives of compute equipment. Yet this is exactly what all the hyperscalers have done.”
GPU generations currently turn over every 18 to 24 months. Blackwell displaces Hopper; Rubin displaces Blackwell. The economic life of the silicon is something like three years, whatever the accounting says. The gap between the six-year GAAP schedule and the three-year economic life is, in Burry’s estimate, not mine, on the order of $176 billion in understated depreciation across the largest hyperscalers over the next three years. That is a real number. It is not a prediction. It is the spread between two disclosed GAAP schedules, one of which (Amazon’s, as of January 2025) has already been corrected downward under pressure from the empirical reality of how fast the silicon is aging out.
This pillar is not under stress. It is already cracking, and we have SEC filings that tell us by how much.
AGI is an LLM with more parameters
The third proposition gets the most religious attention and the least empirical scrutiny. It holds that the path to general intelligence runs through the current architectural paradigm: autoregressive transformer, trained on large-scale text, fine-tuned with human feedback, extended with test-time reasoning. Bigger, better, longer, but the same shape.
LeCun’s counter-position is that language modelling is the wrong substrate. Genuine intelligence requires grounded world-models: predictive representations of physical environment, causal dynamics, three-dimensional space. You cannot learn a world-model from text alone because text is a downstream projection of the world, not the world itself.
Chollet’s counter-position is operationally simpler. Find a task the system has not seen in training, ideally one genuinely novel in structure, and see how it does. Between 2020 and early 2024, LLMs scaled by more than four orders of magnitude in compute. ARC-AGI-1 scores over that period moved from approximately zero to single digits. Scale did not solve this benchmark; scale was not the answer on this specific kind of task.
This is where pillar III connects to pillar IV.
Benchmark progress equals real-world capability
The fourth proposition is the quietest and the most dangerous. The market reads model cards. Model cards report benchmark scores. Benchmark scores go up. The market infers that capability goes up. This inference is the implicit justification for most current AI valuations.
Two lines of work challenge the inference directly.
Schaeffer, Miranda, and Koyejo’s 2023 NeurIPS outstanding paper, Are Emergent Abilities of Large Language Models a Mirage?, showed that the sharp “emergent” jumps widely cited as evidence of rapid capability gain appear only under discontinuous metrics, particularly exact-match accuracy on multi-token answers. Re-score the same model outputs using a continuous metric like token edit distance, and the sharp transitions disappear. The emergence was not in the model. It was in the measurement.
Melanie Mitchell’s work on benchmark contamination is narrower and, in its implications, more uncomfortable. The benchmarks the field uses to measure progress are almost certainly contaminated, in varying degrees, by training-data leakage. Either the benchmark examples appeared in the scrape, or the benchmark format did, or public discussions of the benchmark did. When a model scores 92% on MMLU, we do not know (cannot know, for closed-weight frontier models) how much of that score is skill and how much is retrieval.
Arvind Narayanan and Sayash Kapoor’s related contribution is the capability-reliability gap: the observation that benchmark scores and deployment-ready competence are different quantities, and that the gap between them is widening as benchmarks saturate.
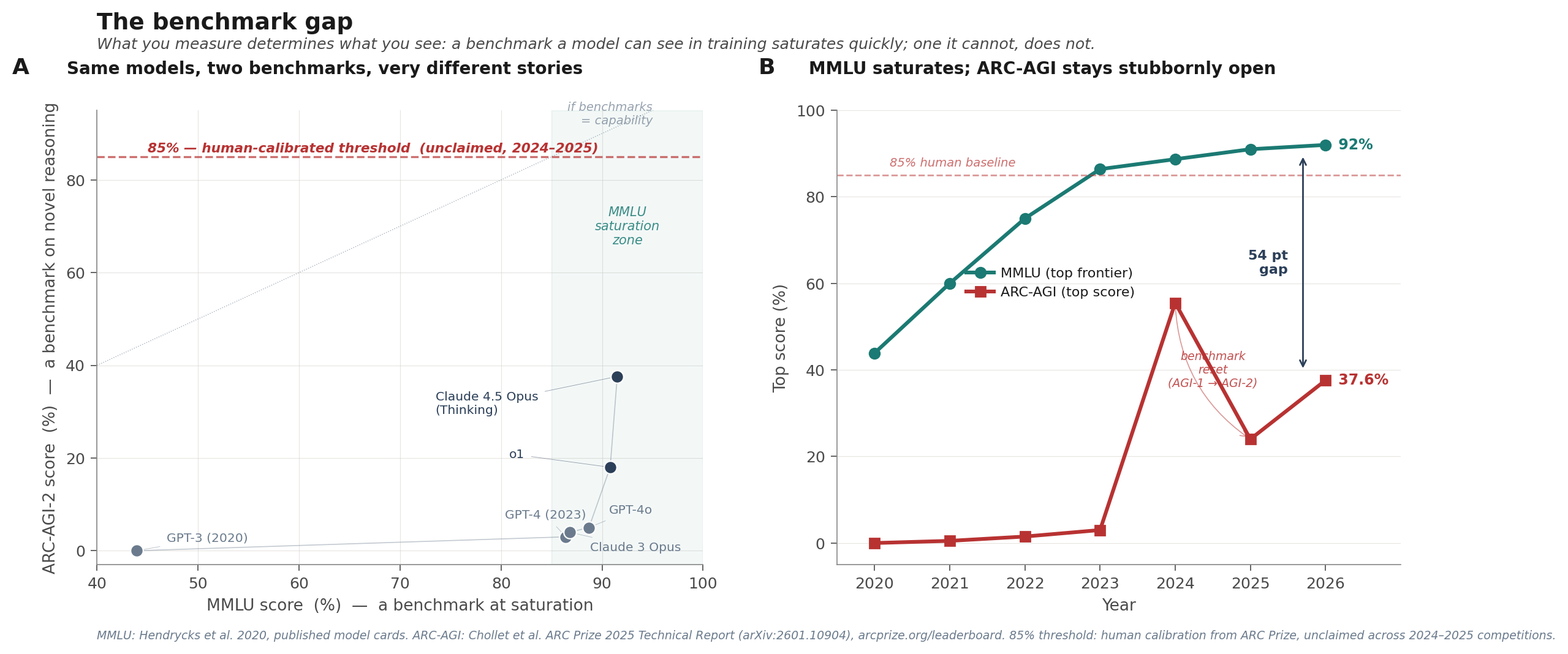
The figure shows the empirical shape of the contamination problem. Same frontier models on two benchmarks: MMLU saturates near 92%; ARC-AGI-2, released March 2025, sits at 37.6% for Claude Opus 4.5 Thinking, the top verified commercial score as of December 2025. The top Kaggle solution across the entire 2025 competition: 24%. The 85% human-calibrated threshold remains unclaimed after two full competition years. A 54-point gap between the saturated benchmark and the novel-reasoning benchmark, for the same frontier models.
Four things, or one?
I have just walked you through four load-bearing assumptions, each with its own camp of defenders and attackers. The natural move at this point, the move nearly every bubble post on Substack makes, is to say: these four assumptions might all hold, or they might all fail, and the bubble is the aggregate bet.
I think this is wrong. I think the four assumptions are not four things. They are four projections of one thing.
Look at them again, read as a sequence:
Pillar I says: the scaling law proxy (cross-entropy loss on web text) tracks capability.
Pillar II says: the accounting proxy (GAAP useful life) tracks economic life.
Pillar III says: the architecture proxy (LLM + parameters) tracks intelligence.
Pillar IV says: the benchmark proxy (MMLU, GPQA, etc.) tracks deployment competence.
Every one of them is a statement about the fidelity of a proxy.
Define, for any proxy i, the fidelity gap F_i as the Kullback-Leibler divergence between the distribution the proxy claims to measure and the distribution it actually measures:
When F_i = 0, the proxy is a perfect measure of what it claims. When F_i > 0, it is not. This is not a metaphor. It is a well-defined quantity, and for each of the four proxies there is already empirical evidence about its value.
The AI bubble, reduced to a single proposition, is a bet that F is small on all four axes. If F is small everywhere, the capital allocation is rational: you are spending real money on real capability, measured by real instruments, amortized against real economic life.
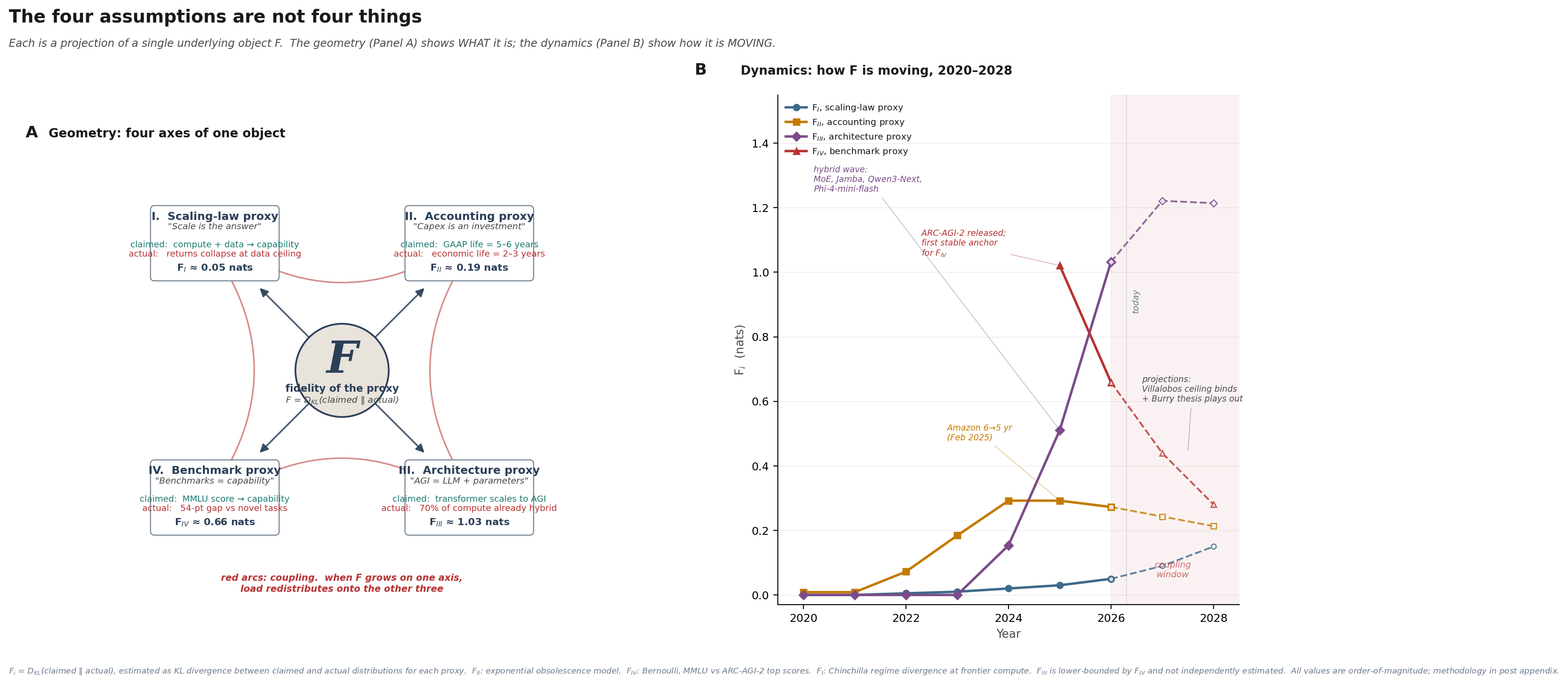
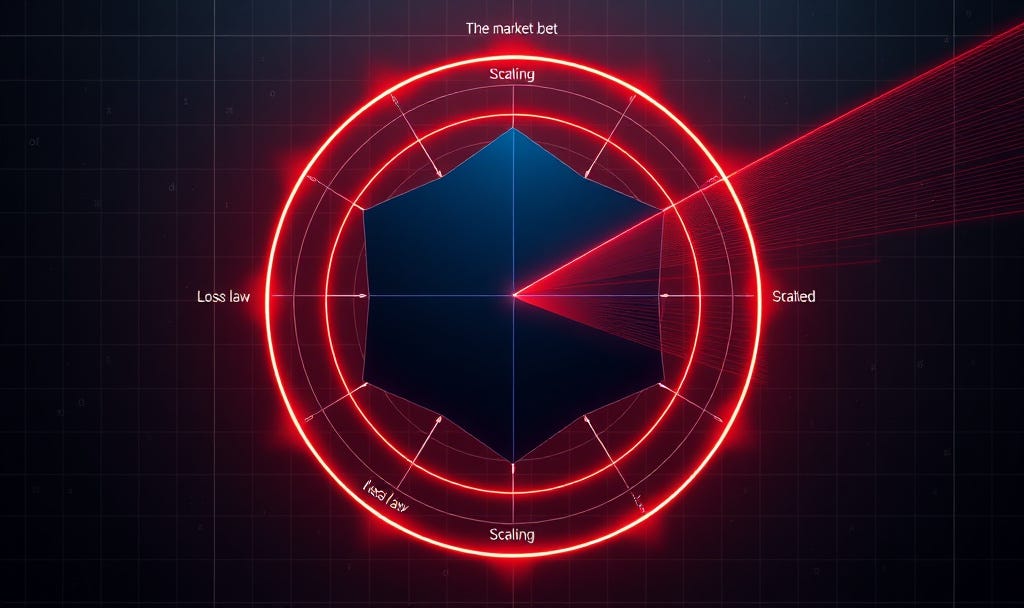
Panel A shows the geometry. F sits at the centre. The four proxies are projections of F onto four axes. The navy arrows point outward because F is the underlying object and each proxy is a slice of it. The red arcs around the perimeter are the coupling: when F grows on one axis, the load does not stay on that axis, because the four proxies are not independent.
Panel B shows the dynamics. F_II (the accounting proxy) has been the most visible to anyone reading SEC filings: rising from near zero in 2020 to about 0.29 nats at its 2024 peak, then starting to decline as hyperscalers correct their schedules (Amazon was first in February 2025). F_IV (the benchmark proxy) only became well-defined in 2025 with the release of ARC-AGI-2 as a stable anchor; its starting value of about 1.0 nat has been declining as the benchmark itself gets partially solved, but the level remains far above zero. F_I (the scaling proxy) has been negligible historically and becomes material only in the 2026-2028 projection window as the Villalobos data ceiling binds.
The most interesting of the four is F_III. The architecture proxy was zero through 2023 because the industry’s paradigm commitment (”transformer scales to AGI”) matched the industry’s actual compute allocation (nearly 100% pure transformers). Then something happened. Starting in 2024, frontier labs began quietly deploying compute on architectures that are not pure transformers: Mixture-of-Experts in more than 60% of frontier models by 2025; hybrid attention plus state-space systems (Jamba, Qwen3-Next, Phi-4-mini-flash, which is 75% Mamba layers) shipping as state-of-the-art. By 2026 my estimate is that the share of frontier-lab compute still on pure autoregressive transformers has fallen to about 30%. The public commitment to the paradigm has not changed. The GPUs have.
What is next
What are the markets are actually pricing, where the thermometer is, and what to do with the reading! Nvidia is the cleanest signal in the system: its multiple is the market's revealed estimate of how much capex the rest of the stack will keep buying. The capex-to-monetisable-revenue gap, on the order of $300B annualised at present, is the cleanest stress test of that estimate. Infrastructure bets can be right even when 80% of the players go to zero, but Mauboussin's base rate is uncomfortable: the canonical pattern in technology cycles is that the technology wins and the investors lose, which is the asymmetry Acemoglu and Grantham keep flagging while Andreessen keeps not flagging it.
Sources and further reading
Hoffmann, J., Borgeaud, S., Mensch, A., et al. (2022). “Training Compute-Optimal Large Language Models.” arXiv:2203.15556.
Villalobos, P., Ho, A., Sevilla, J., Besiroglu, T., Heim, L., Hobbhahn, M. (2024). “Will we run out of data? Limits of LLM scaling based on human-generated data.” Proceedings of ICML 2024, 235:49523–49544.
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., Gal, Y. (2024). “AI models collapse when trained on recursively generated data.” Nature 631, 755–759.
Schaeffer, R., Miranda, B., Koyejo, S. (2023). “Are Emergent Abilities of Large Language Models a Mirage?” NeurIPS 2023 Outstanding Paper.
Chollet, F. (2019). “On the Measure of Intelligence.” arXiv:1911.01547.
Chollet, F., Knoop, M., Kamradt, G., Landers, B. (2026). “ARC Prize 2025: Technical Report.” arXiv:2601.10904.
Narayanan, A., Kapoor, S. (2024). AI Snake Oil. Princeton University Press.
Narayanan, A., Kapoor, S. (2025). “AI as Normal Technology.” Knight First Amendment Institute, April 15.
LeCun, Y. (2022). “A Path Towards Autonomous Machine Intelligence.” OpenReview preprint.
Mitchell, M. (2023). “How do we know how smart AI systems are?” Science 381 (6654).
Hendrycks, D., et al. (2020). “Measuring Massive Multitask Language Understanding.” arXiv:2009.03300.
Amazon, Inc. (2025). Form 10-K, fiscal year 2024, Item 7 (change in estimated useful life of servers effective January 1, 2025).
Burry, M. / Scion Asset Management (November 2025). Public disclosures and subsequent analysis, CNBC and FT coverage.
Amodei, D. (2024). “Machines of Loving Grace.” Essay, darioamodei.com.
Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” arXiv:2001.08361.